Automated detection on the security of the linked-list operations
·发表年份:
2022年
·原文链接:
https://journal.hep.com.cn/fcs/EN/10.1007/s11704-020-0312-6
·引用格式:
Hongyu KUANG, Jian WANG, Ruilin LI, Chao FENG, YunFei SU, Xing ZHANG. Automated detection on the security of the linked-list operations. Front. Comput. Sci., 2022, 16(2): 162201
公众号推文链接:
链表操作安全性的自动检测
01 导读
随着OS(操作系统)针对漏洞利用采取的措施越来越完善,大多数C/ C++内存漏洞中栈相关的漏洞逐渐减少,而堆相关漏洞日益突出。众所周知,软件程序是数据结构和算法的融合,因此,如果对数据进行不安全的操作,可能会导致不可预知的后果。链表作为与堆内存密切相关的一类数据结构,在存储、搜索和修改数据元素方面都十分方便,因此常在实际软件生产中得到应用。链表的创建和删除包含了堆内存的分配和释放,如果形成的组合不规范,便可能产生堆漏洞。如果程序员在创建或删除链表时不注意代码的规范,程序便更有可能面临由于堆内存管理疏忽而引起的一系列潜在漏洞问题。因此,在编程中使用链表时,十分有必要检查算法实现链表的效果,例如,是否在空链表上执行、是否执行安全边界条件的检测等。为了提高代码安全性,AddressSanitizer(ASan)经常被使用来进行动态检测,但是运用ASan开销大,代码覆盖率也相对较低。然而,一些检测范围较广的静态检测工具,如Coverity和Cppcheck,在检测特定目标时精度和效率又较低,很难找到一个现有的方法来自动检查链表操作的安全性。因此,本文提出了一种自动检查链表上安全代码规范的方法。
02 方法介绍
对链表的操作是通过一段代码来完成的,这段代码可能只是一个文件中的一个函数,甚至是一个函数中的几行代码。为了提高检测的效率和准确性,本文将整个过程分为三个阶段。通过前两个阶段,使用两种神经网络模型来区分链表操作的类型,最后根据它们的类别进行相应的安全检查。该过程的框架如图1所示,神经网络模型接收一个标记序列作为输入数据,并使用BLSTM模型构建二分类器,使用CNN模型构建三分类器,最后,用我们定义的三种安全代码规范输出结果。
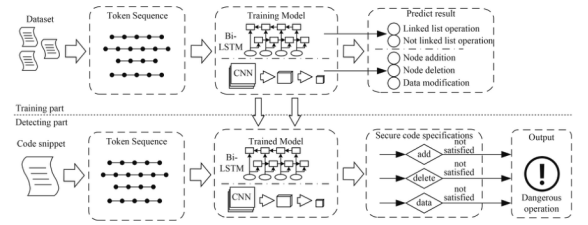
图1 过程框架概述
第一阶段:判断一个代码片段是否是链表操作
近年来,深度学习已被广泛应用于程序理解。源代码的建模可以分为三类:标记序列、抽象语法树(AST)和图结构(CFG、DFG)。通常,AST、CFG和DFG包含有关程序的更多信息。然而,若代码片段缺少头文件和宏,就可能包含比通常表单更少且相当不准确的信息。此外,这两种建模方法比较复杂,因此会产生更多的开销。
因此,我们选择令牌序列并以一种模糊的方式建模和解析C/ C++代码片段,即使无法提供工作构建环境或缺少部分代码,模糊解析器也可以根据词法和句法分析将每个程序语句分割为标记。令牌序列主要包括两种类型的令牌:符号和标识符。一般来说,在任何C/ C++文件中都有一定数量的符号,例如一元操作符、圆括号和分号,但是标识符的形式是可变的。首先确定整个代码中的函数名和变量名,然后用占位符替换这些变量名和函数名,因此,处理的标识符类型被控制在一定范围内,以减轻词汇表外的问题。经过处理的标识符和符号的总词汇量为173,由于173维向量的符号和标识符的数量是固定的,故采用单热嵌入法进行词嵌入。并且,由于标记序列的长度是可变的,故本文将标记序列的大小设置为300个标记,若序列长度大于300,则将截断超出的部分,若序列长度小于300,则将对不足的部分补零向量。为了提取不同标记之间的关系,将BLSTM作为神经网络的主要框架,使用MLP作为最终的分类器。本文使用带有150个单元格的单层BLSTM和带有64和32两个隐藏层的全连接分类器,在BLSTM层和密集层之后使用PReLU作为激活层,然后使用sigmoid函数作为最终输出的激活,并在每个激活层之后,添加Dropout来缓解过拟合。
第二阶段:将链表操作分为三类
本文将链表的操作分为以下几类:节点的添加、节点的删除以及节点数据的赋值或修改,这些操作被视为原子操作,即链表基本功能的实现。作为原子操作,它们的特征粒度更细。例如,节点的增加和删除形式不同,但都涉及到链表节点的断开和重新连接的过程。因此,提取这些特征需要更加谨慎。与前一阶段不同的是,在这一阶段,没有规范化所有的标识符,而是保留了与链表操作语义相关的通用标识符,例如malloc、free、next和prev,保留标识符词汇表的大小为11。此外,用于特征提取的神经网络也不同于之前的框架BLSTM,本文使用CNN作为主要框架来捕获代码片段中的局部详细特征,然后使用带有Softmax函数的MLP作为最终的分类器,本文使用32个核大小为3的一维卷积滤波器和两个隐藏层为32和16的全连接分类器。对于链表操作的代码段,数据量减少,因此节点之间的关系变得相对紧密,长序列依赖问题可以忽略。与LSTM相比,CNN可以提高训练速度,降低训练成本。
第三阶段:检查链表操作的代码规范
本文定义了几个安全代码规范如下:第一,添加节点时是否有内存分配的状态检查;第二,目标节点的内存块在节点删除时释放后是否被清空;第三,在分配或修改节点数据时,是否对分配数据的有效性进行检查。
在添加节点时,如果分配目标内存块失败,那么再使用目标内存时,程序可能会崩溃。删除节点时,应回收其内存块,否则将存在内存泄漏的潜在危险。在分配节点数据时,如果数据来自外部输入,但没有对输入数据进行类型或大小检查,则可能导致输入数据与节点数据的字段不一致,从而导致缓冲区溢出。由于代码片段中可能有多个原子操作,例如在添加新节点后初始化节点,因此需要分别检测这些规范。对于包含添加节点操作的代码段,如果它包含分配内存的操作,则应该有一个条件判断来检查请求的内存是否为空,否则是不安全操作。如果不包括内存分配的操作,则只是断开链表和组合链表的过程,并认为这一步符合安全规范。对于包含节点删除操作的代码段,为了保障安全,需要判断是否存在释放内存的自由操作。如果存在内存释放的自由操作,但释放后的内存没有设置为NULL,则被认为是不安全的。对于包含数据分配的代码片段,我们首先需要确定分配的数据源。如果是外部输入,因缺乏检查数据大小的条件,故被认为是不安全的,如果是一个内部值,则通常是一个安全值。
03 主要贡献
帮助程序员检查大量源代码中的危险操作,通过静态分析将源代码模糊地解析为令牌序列,然后通过神经网络模型提取这些令牌之间的关系,来识别链表的操作是否符合安全规范,包括节点的增加、节点的删除、节点数据的赋值或修改。并解决了以下问题:
(1)如何识别链表操作。
(2)如何对细粒度链表上的操作进行分类。
(3)如何检查链表操作的规范。
04 实验结果总结
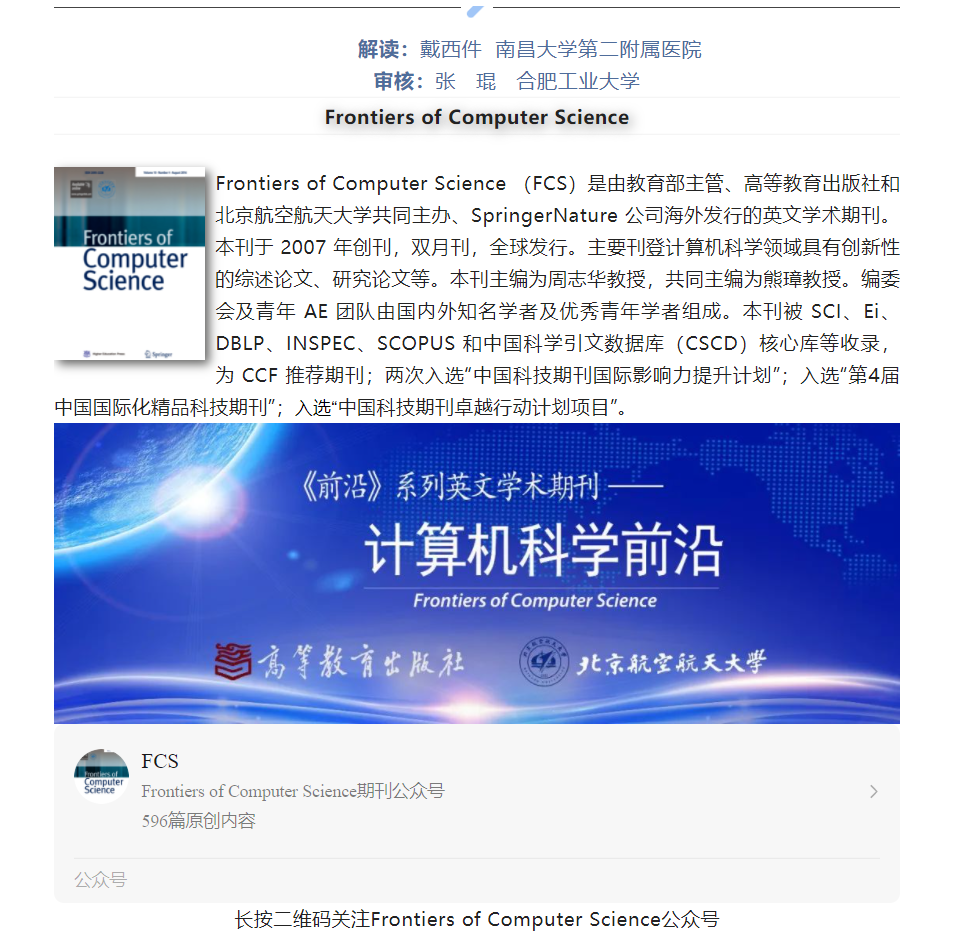
本文从GitHub开源社区收集了两个数据集,DATA-BIN(二进制分类)和DATA-MULTI(三种分类)。DATA-BIN的数据为函数粒度,包括4030个链表操作和19945个非链表操作。DATA-MULTI的粒度更细,增加6352个节点,删除3896个节点,分配或修改3600个节点数据。在DATA-BIN上,BLSTM被用作基线模型。在DATA-MULTI上,使用Conv1d作为基线模型。此外,本文还为这个多分类模型定义了几个评估指标。表示基于类别的不同指标的平均值,表示基于每个类别数量的不同指标的平均值。评价结果见表1。
表1 DATA-BIN和DATA-MULTI的评价结果